
Waltz Server
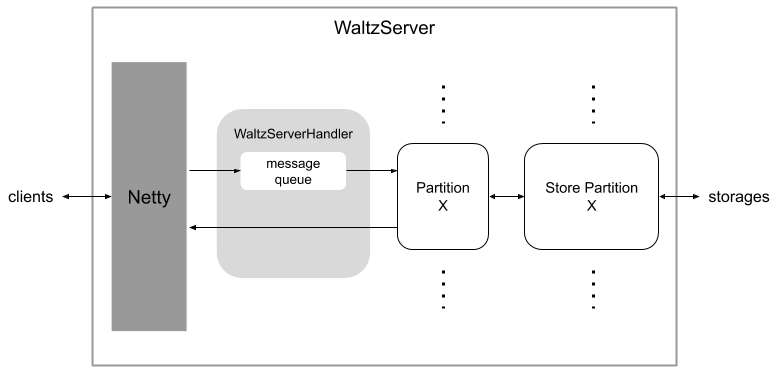
Waltz Server receives messages from the clients. We implemented the networking layer on Netty. Netty calls WaltzServerHandler for each message. Messages are enqueued into the message queue and dispatched to partition by the message handler thread running in WaltzServerHandler.
A partition object represents a Waltz log partition. The persistent log data are replicated and stored in multiple storage servers. Actual interaction with storages are done by a store partition object. A partition object and a store partition object are created when the partition is assigned to the server.
Partition Object
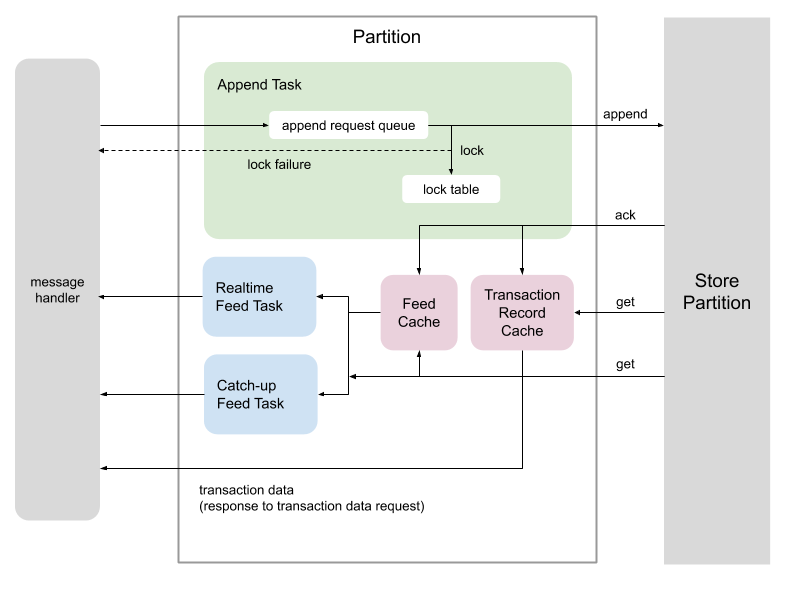
Each partition object has three tasks (threads), Append task, Realtime Feed task, and Catch-up Feed Task.
An append request is immediately place in the append request queue in the append task object. The thread of the append task polls a request from the queue and tries to acquire locks if the append request contains any lock request. If locking fails, the task sends a lock failure message to the client. If there is no lock failure, the transaction information is passed to the corresponding store partition. A store partition works as a proxy to storage servers. When the success of append operation is acknowledged, the transaction information is stashed into the feed cache and the transaction record cache.
Store Partition Object
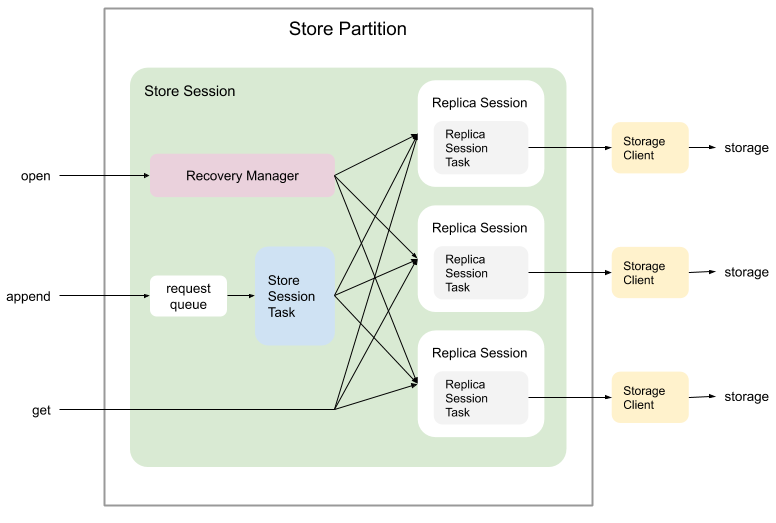
A Store Partition object manages read/write to storage servers. A store partition represents a partition which is replicated to multiple storage servers. Read/write operations are performed in a context of a session called a store session. Actual read/write operations to a partition on each storage server is also performed in a session called a replica session.
When a store session is created, replica sessions are created for all known storage servers. Then, a recovery manager is created and starts a recovery to resolve any unresolved write operations and truncate any dirty data on storage servers.
An append request are first placed in the request queue. The store session task polls requests from the queue, batch them up, and sends to all available storage servers through replica sessions. When the number of successful writes reach the quorum, the notification is propagated to the requester through a callback. If a storage is falling behind, the append request to that storage is discarded, and the replica session task starts catch-up process which transfers transaction data from other storages to this storage.
Partition Metadata
Waltz Server stores the metadata of partitions in Zookeeper for recovery. The ZNode path is <cluster root>/store/partition/<partition id>. They include the generation numbers, the store session ID, and the states of replicas (the replicated partitions on storage servers). They are written when a new store session is created.
Partition Metadata
| Field | Data Type | Description |
|---|---|---|
| Generation | int | The generation number |
| Session ID | long | The current store session ID |
| Map of Replica ID to Replica State (repeated) | ||
| Replica ID | ReplicaID | The replica ID |
| Replica State | ReplicaState | The replica state |
ReplicaId
| Field | Data Type | Description |
|---|---|---|
| Partition ID | int | The partition ID |
| Storage Node Connect String | String | The storage node connect string |
ReplicaState
| Field | Data Type | Description |
|---|---|---|
| Replica ID | ReplicaID | The replica ID |
| Session ID | long | The ID of the store session that this replica is currently engaged. |
| Closing High-water mark | long | The high-water mark when this store session closed. It is ReplicaState.UNRESOLVED when the session starts. This field is set by Recovery Manager when the closing high-water mark of the session is resolved. |
Recovery Procedure
A recovery procedure is applied whenever Store Session Manager creates a new store session. The followings are the steps of the recovery.
- Get new store session ID by updating Partition Metadata in Zookeeper. CAS is used to avoid race conditions.
- Create new Replica Sessions
- Create a new Store Session with the new session ID and the new Replica Sessions.
- Open the Store Session
- Open each Replica Sessions and start Replica Session Task
- In each Replica Session Task,
- Wait for a connection to establish
- After connected,
- Get the Replica State from Partition Metadata
- If the Replica State and the actual storage is inconsistent,
- Truncate the transaction log to the low-water mark saved in the storage
- Otherwise,
- If the closing high-water mark is already set,
- Truncate the log to it.
- Otherwise,
- If the max transaction ID is greater than the low-water mark, propose its max transaction ID as the closing high-water mark.
- If the closing high-water mark is already set,
- Start catch-up to any replica ahead of itself
- Check if the closing high-water mark is resolved (a quorum is established)
- If yes,
- Set the low-water mark
- If the replica has fully caught up,
- Truncate any dirty transactions
- Otherwise,
- Continue catching-up
- Update Partition Metadata
- For each Replica State,
- If the replica is clean,
- Set the session id to the new store session id
- Set the closing high-water mark to ReplicaState.UNRESOLVED
- Else if the closing high-water mark is ReplicaState.UNRESOLVED,
- Set the closing high-water mark to the resolved closing high-water mark leaving the session id unchanged
- Otherwise,
- Leave the replica state unchanged.
- If the replica is clean,
- For each Replica State,
Example 1 (Adding single replica)
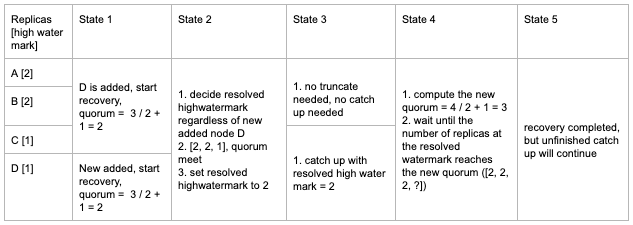
Example 2 (Adding multiple replicas)
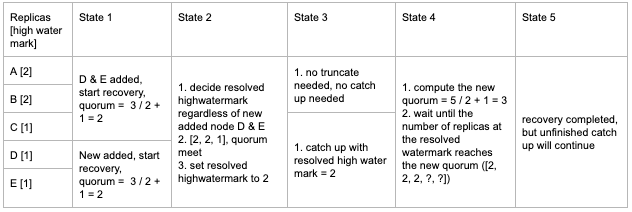
Example 3 (Removing single replica)
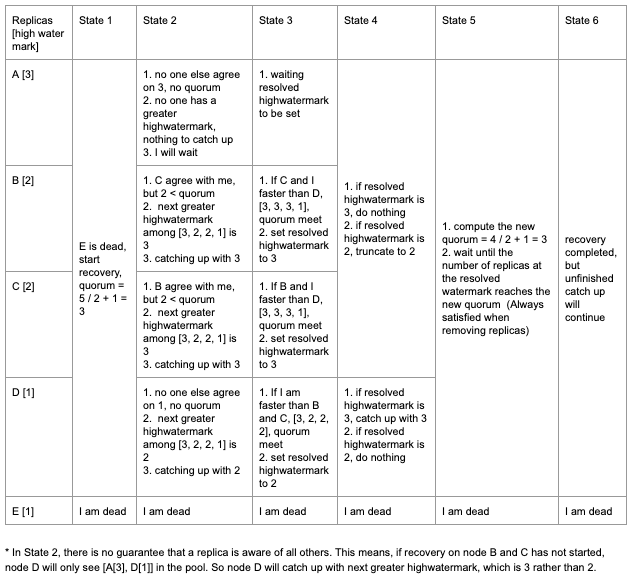
Example 4 (Removing multiple replicas)
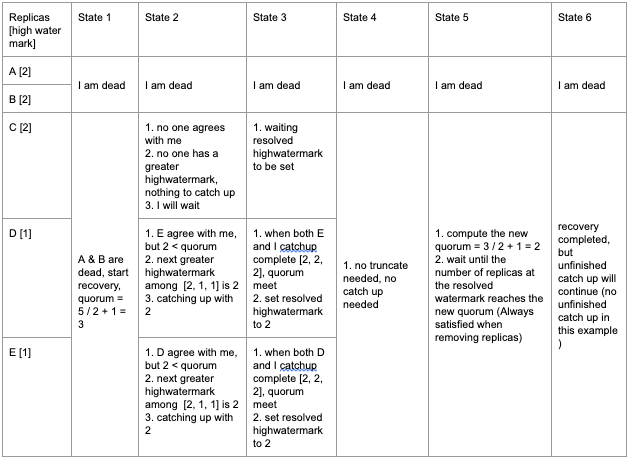
Quorum Checking in the Recovery Process
Quorum checking in the recovery process has a subtle difference from quorum checking in the write operation. We need to find out the highest high-water mark that majority of replicas agree on. In the following figure, the high-water marks of Replica A, B, and C are HA, HB, and HC, respectively. The highest high-water mark that a majority of replicas agree is HA.

We do the selection by having replicas vote on high-water marks. A replica with the high-water mark X votes for any high-water mark H that is equal to or less than X. So, Replica A votes for { HA, HC }, Replica B votes for { HA, HB, HC }, and Replica C votes for { HC }. Clearly HA is the highest high-water mark that a majority replicas vote. This is correct since all transactions above HA have no chance of getting the write quorum, thus they are uncommitted. All transactions at HA or below have the write quorum, thus it is safe to declare they are committed.
This works fine when all replicas are participating. However, we cannot expect all replicas are available all the time. There may be inaccessible storage servers during the recovery process which may have caused the recovery process in the first place. So, the quorum checking must take that into consideration.

If Replica B is inaccessible, only Replica A and C vote. The highest high-water mark with majority vote is HC, but this is wrong. The high-water mark is undecidable in this situation.
The solution is to detect the undecidable situation by counting inaccessible replicas and wait until it becomes decidable. It becomes decidable when enough (not necessarily all) replicas come online. In the above case, it becomes decidable when Replica B comes back. Another situation that it becomes decidable is Replica C catches up with Replica A.

Undecidability is detected as follows. We examine voted high-water marks in descending order. If the number of votes is not reaching the quorum, the number of votes + the number of offline storages is tested. If it is equal to or greater than the quorum, the high-water mark is not decidable. In the above example, the quorum is two votes. HA is examined first. It doesn't have enough votes (only 1 vote). But, # of votes (1) + # of offline storage (1) is two. This is equal to the quorum, thus the true high-water mark is undecidable.
Every time the situation changes, the recovery process re-evaluate the quorum.